In a previous blog post, we discussed the installation of ProxySQL and its configuration system. In today’s post, we’ll set up ProxySQL to work in a MySQL Replication environment managed by ClusterControl. We will take a look at the metrics it provides to a DBA, and how this data can be used to ensure smooth operations.
Why ProxySQL?
This is very valid question most of you are probably asking. You either already are using some kind of proxy layer (be it HAProxy or MaxScale perhaps), or you have concluded that you don’t really need a proxy layer in your setup. Why bother try and test another proxy? How can it help you in your daily operations?
ProxySQL’s biggest advantage is this - it is a piece of software created by DBA’s, for DBA’s. It’s aim is to help with common, sometimes very frustrating problems. Have you ever been in a situation where a not optimal an awful query was killing your databases, yet you could not do anything about it because it needed to be modified in the application that is maintained by somebody else? Have you been asked to diagnose issues caused by database nodes that constantly switch between online and offline? Have you ever wanted a way to see your query traffic, almost in real time, without a need to collect the data first (from slow logs or tcpdump) and then process it? Or maybe you’d like to execute graceful switchovers and failovers, as your application does not handle broken transactions well? ProxySQL can assist in such cases.
Setting up ProxySQL to work with MySQL replication
Define hostgroups
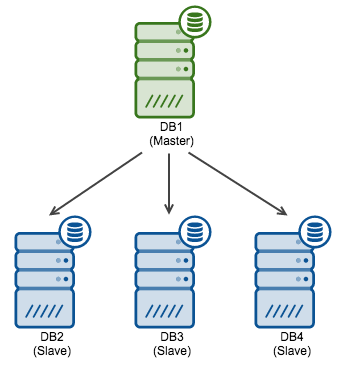
As we described in this previous post, ProxySQL uses a concept of hostgroups - a group of different backends which serve the same purpose or handle similar type of traffic. When it comes to replication, at a minimum two types of backends come to mind - a master, which handles writes (and also reads, if needed) and slave (or slaves), which handles read-only traffic. In this example we are not going to need anything more than those two hostgroups. To create them, we need to connect to the ProxySQL management interface and run queries like this:
MySQL [(none)]> INSERT INTO mysql_servers (hostgroup_id, hostname, port, max_replication_lag) VALUES (0, '172.30.4.120', 3306, 20);
Query OK, 1 row affected (0.00 sec)
MySQL [(none)]> INSERT INTO mysql_servers (hostgroup_id, hostname, port, max_replication_lag) VALUES (1, '172.30.4.113', 3306, 20);
Query OK, 1 row affected (0.00 sec)
MySQL [(none)]> INSERT INTO mysql_servers (hostgroup_id, hostname, port, max_replication_lag) VALUES (1, '172.30.4.181', 3306, 20);
Query OK, 1 row affected (0.00 sec)
What we did here was to create three backends, 172.30.4.120, 172.30.4.113 and 172.30.4.189. The first of them was assigned to hostgroup ‘0’, as this host acts as a master. Therefore this hostgroup will be our ‘write’ hostgroup. Remaining hosts were assigned to a hostgroup ‘1’, which will be used to store our slaves. Please note we did set the max_replication_lag setting which means that slaves with a lag greater than 20 will be shunned in the proxy and traffic won’t be directed to them. This creates a possibility that neither of our slaves will be available for the read-only traffic. Therefore we need to make one more step:
MySQL [(none)]> INSERT INTO mysql_servers (hostgroup_id, hostname, port, max_replication_lag) VALUES (1, '172.30.4.113', 3306, 20);
Query OK, 1 row affected (0.01 sec)
We’ve added our master, 172.30.4.113 to the ‘read-only’ hostgroup - we want it to be there in case none of the slaves are available due to high replication lag. Obviously, our master won’t be affected by lag, therefore it will always be available.
What we could also have done is to set different weights between .113 and the remaining hosts - this would keep our master almost free of the read-only traffic as long as one of the slaves is available. This would require changes in the weight settings after the failover (low weight has to be set on the new master and regular, higher weight would have to be set on the old master. Unfortunately, at the time of writing, ClusterControl does not support setting these weights. Therefore we will have to accept an evenly split read-only traffic across all nodes in the topology.
Define application users
Next required step would be to create users in ProxySQL. ProxySQL works as a proxy - application connects to it, authenticates against it and then ProxySQL finds a suitable connection to the backend (that matches user, schema, collation and some other parameters). If such connection does not exists, ProxySQL opens a new one. The point is that the application talks only to the proxy. Therefore ProxySQL has to have a list of users which are allowed to connect to the database. Our application will use a single user:
MySQL [(none)]> INSERT INTO mysql_users (username, password, active, default_hostgroup, max_connections) VAL
UES ('sbtest', 'sbtest', 1, 0, 200);
Query OK, 1 row affected (0.00 sec)
What we did here was to create an user ‘sbtest’ with password of ‘sbtest’. We set the user as ‘active’ and we also set the maximum number of connections for this user to 200. Very important bit is the default hostgroup. As we discussed in the previous post, ProxySQL uses a chain of query rules to figure out the routing. If none of the rules apply to a query, query will be routed to the default hostgroup for the user, which created the connection. In our case all queries executed by user ‘sbtest’ which won’t match any of the query rules (which we are going to create in next step), will be routed to the hostgroup ‘0’ - our ‘write’ hostgroup.
Define query rules
As mentioned earlier, ProxySQL uses query rules to route traffic. Those rules can create complex chains and distribute traffic across multiple hostgroups. In our case there’s no need for too much complexity - what we want is to route all SELECTs except for SELECT ... FOR UPDATE to a ‘reader’ hostgroup (‘1’ in our case) and route remaining traffic (DDL, DML, anything else than SELECT) to the master. Rules are located in ‘mysql_query_rules’ table which is parsed similarly to iptables chains - starting from the first rule, trying to match a query. If a rule doesn’t match, the query is tested against another one. If there is no match, the query is routed to the default hostgroup for the user that executed a query.
In our case two rules are needed. First one:
MySQL [(none)]> INSERT INTO mysql_query_rules (active, match_pattern, destination_hostgroup, cache_ttl) VALUES (1, '^SELECT .* FOR UPDATE', 0, NULL);
Query OK, 1 row affected (0.00 sec)
We are checking if the query is not by chance a SELECT … FOR UPDATE. If it is, we want it to be routed to hostgroup ‘0’ - our ‘writer’ hostgroup. If a query is not SELECT … FOR UPDATE, we’ll check another rule:
MySQL [(none)]> INSERT INTO mysql_query_rules (active, match_pattern, destination_hostgroup, cache_ttl) VALUES (1, '^SELECT .*', 1, NULL);
Query OK, 1 row affected (0.00 sec)
Here we are checking if a query is a regular SELECT. If so, it’ll be routed to hostgroup ‘1’ - our ‘reader’ hostgroup. If not, there are no more rules in the chain so the default hostgroup for our application user will be used (hostgroup ‘0’).
Setting up the monitoring module and healthcheck timeout
In this step we are going to setup the correct access credentials for the ProxySQL monitoring module. We are also going to change some of default timeouts related to the healthchecks executed by ProxySQL. As we wrote in the previous blog post, the monitoring module in ProxySQL does not take part in checking the health of the nodes. It will be needed in our case, though - we’ve set a limit for the maximal replication lag we can accept. We will also want ProxySQL to watch read_only flags in order to understand topology changes invoked by ClusterControl. Both those features require that you correctly setup the monitoring module.
We start first with creating a user on our master host - this user will be used by the monitoring module:
mysql> GRANT REPLICATION CLIENT ON *.* TO monuser@172.30.4.90 IDENTIFIED BY 'monpass';
Query OK, 0 rows affected (0.00 sec)
Next, we need to set the correct user and password to the monitoring module. In the past, UPDATE on ‘global_variables’ table was the only way to change settings in ProxySQL. Recently, support for more ‘MySQLish’ way of setting variables was added and MySQL DBA’s can benefit from another syntax that’s imprinted in their consciousness: SET variable = ‘value’
mysql> SET mysql-monitor_username='monuser';
Query OK, 1 row affected (0.00 sec)
mysql> SET mysql-monitor_password='monpass';
Query OK, 1 row affected (0.00 sec)
Finally, we want to update 'mysql-connect_timeout_server_max' to 20 seconds (20000 milliseconds).
mysql> SET mysql-connect_timeout_server_max=20000;
Query OK, 1 row affected (0.01 sec)
We want ClusterControl to manage the failover and the failover process (unless something went very bad) takes between 10 and 20 seconds. ProxySQL has to be able to wait up to 20 seconds to allow the failover to be graceful.
Define ‘read’ and ’write’ hostgroups and load the new configuration
Here, the final steps needed to complete our setup. We need to let ProxySQL know to which hostgroups our slaves (hosts with read_only=1) and masters (hosts with read_only=0) should belong. We do this by adding an entry to the ‘mysql_replication_hostgroups’ table:
MySQL [(none)]> INSERT INTO mysql_replication_hostgroups (writer_hostgroup, reader_hostgroup) VALUES (0, 1);
Query OK, 1 row affected (0.00 sec)
As you may remember from our previous blog post, ProxySQL does not update runtime configuration when you make a change - you need to explicitly load them. If you want to have them persistent, you also want to save them to disk. We need to do these steps now.
First, changes in mysql_users:
MySQL [(none)]> LOAD MYSQL USERS TO RUNTIME;
Query OK, 0 rows affected (0.00 sec)
MySQL [(none)]> SAVE MYSQL USERS TO DISK;
Query OK, 0 rows affected (0.03 sec)
Next, query rules:
MySQL [(none)]> LOAD MYSQL QUERY RULES TO RUNTIME;
Query OK, 0 rows affected (0.00 sec)
MySQL [(none)]> SAVE MYSQL QUERY RULES TO DISK;
Query OK, 0 rows affected (0.05 sec)
Variables:
MySQL [(none)]> LOAD MYSQL VARIABLES TO RUNTIME;
Query OK, 0 rows affected (0.00 sec)
MySQL [(none)]> SAVE MYSQL VARIABLES TO DISK;
Query OK, 54 rows affected (0.02 sec)
And finally, mysql_servers and mysql_replication_hostgroups:
MySQL [(none)]> LOAD MYSQL SERVERS TO RUNTIME;
Query OK, 0 rows affected (0.01 sec)
MySQL [(none)]> SAVE MYSQL SERVERS TO DISK;
Query OK, 0 rows affected (0.08 sec)
The order is not very important, but there is one single notable exception - you want to make sure that all changes in variables are loaded ‘to runtime’ and monitoring users have been created on the MySQL side before you apply changes to mysql_replication_hostgroups. Applying changes to this table starts the ‘topology detection’ mechanism which will change your mysql_servers table if it’s not able to connect to backends - and this can happen only after access credentials have been set in the ProxySQL variables.
At this point, your proxy is ready to handle switchovers executed using ClusterControl. Let’s take a look at how it works.
Real world issues ProxySQL can help you to solve
Graceful switchover
In this example we’ll use sysbench as our ‘application’ - it’s good enough for that. Traffic will be generated and we’ll be watching the progress every second.
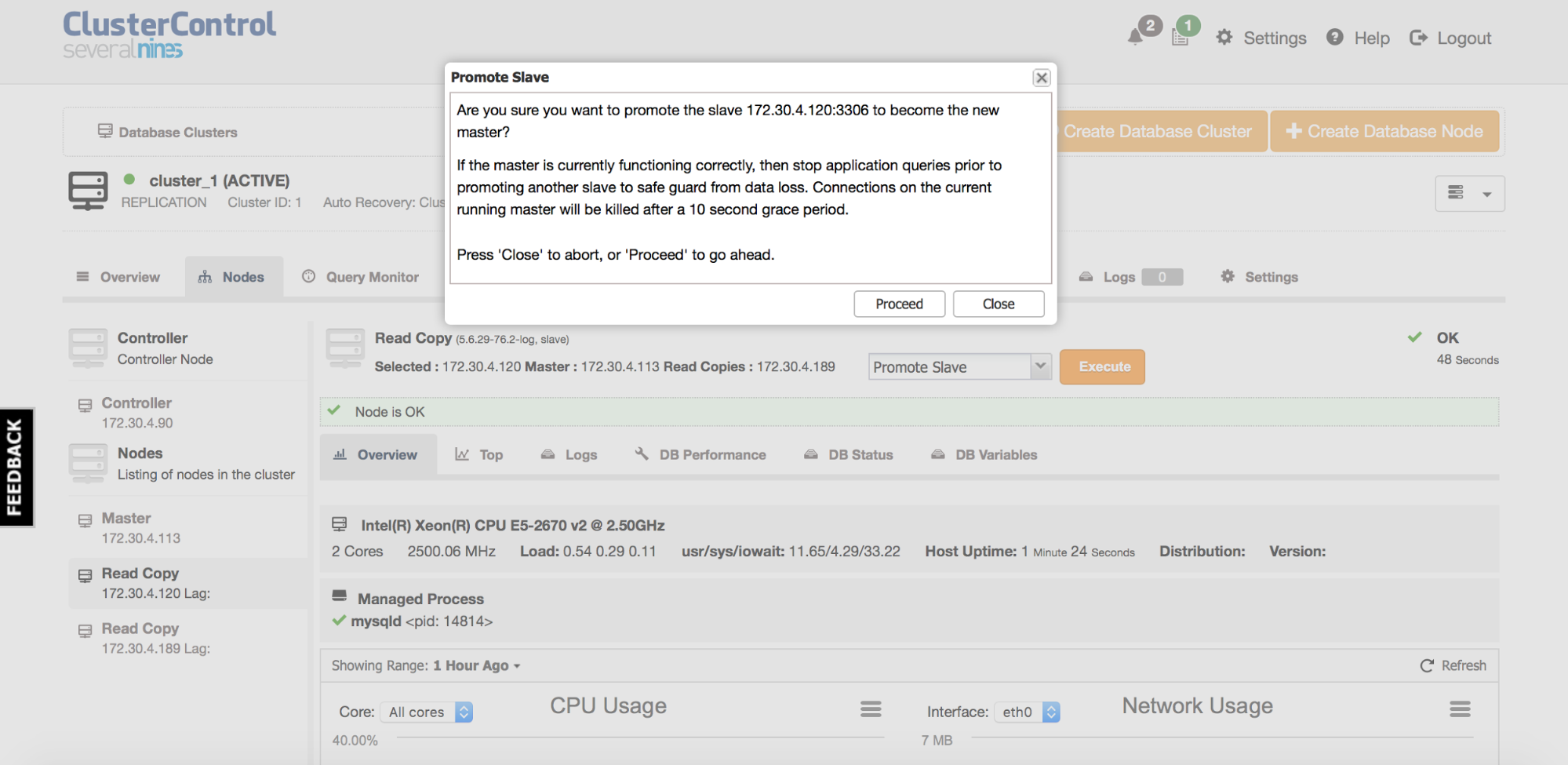
To accomplish switchover, all you need to do is to initiate it from the ClusterControl (Nodes tab -> choose a slave -> Promote Slave)
[ 237s] threads: 6, tps: 0.00, reads: 4385.89, writes: 1256.97, response time: 45.89ms (95%), errors: 0.00, reconnects: 0.00
[ 238s] threads: 6, tps: 0.00, reads: 2208.06, writes: 631.02, response time: 161.20ms (95%), errors: 0.00, reconnects: 0.00
[ 239s] threads: 6, tps: 0.00, reads: 4275.01, writes: 1225.00, response time: 75.14ms (95%), errors: 0.00, reconnects: 0.00
[ 240s] threads: 6, tps: 0.00, reads: 479.00, writes: 124.00, response time: 16.76ms (95%), errors: 0.00, reconnects: 0.00
[ 241s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 242s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 243s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 244s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 245s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 246s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 247s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 248s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 249s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 250s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 251s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 252s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
^@[ 253s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 254s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 255s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 256s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 257s] threads: 6, tps: 0.00, reads: 3285.09, writes: 951.03, response time: 17.65ms (95%), errors: 0.00, reconnects: 0.00
[ 258s] threads: 6, tps: 0.00, reads: 5630.94, writes: 1608.98, response time: 22.25ms (95%), errors: 0.00, reconnects: 0.00
[ 259s] threads: 6, tps: 0.00, reads: 6018.01, writes: 1713.00, response time: 16.76ms (95%), errors: 0.00, reconnects: 0.00
As you can see, no error happened and no transaction had to be rolled back - our application stalled for roughly 16 seconds but except for that, there was no impact whatsoever. Those 16 seconds are a result of how ClusterControl does the switchover - we allow some time for open transactions to close, to make sure ClusterControl won’t kill your queries as long as it’s not really necessary.
Graceful failover
ProxySQL, when configured as shown in this post, can handle (out of the box) failovers initiated by external tools. ClusterControl, at the time of writing does not support automated failover for MySQL Replication (we are working on this feature so it should become available in the next version) therefore we used another tool, MHA, to showcase this feature.
Detailed guide on setting up MHA is out of the scope of this blog post. We used the following configuration which should work with most ClusterControl deployments out of the box. This is not a production-grade configuration. You should define at least a secondary check script, to make sure you can check the status of the cluster using another way than direct SSH. You may also need to define a shutdown script or IP failover script if you use some kind of virtual IP pointing to your master. Having said that, this particular configuration will do for our demo.
[server default]
# mysql user and password
user=cmon
password=cmon
ssh_user=root
# working directory on the manager
manager_workdir=/var/log/masterha/s9s_app
# working directory on MySQL servers
remote_workdir=/var/log/masterha/s9s_app
[server1]
hostname=172.30.4.113
[server2]
hostname=172.30.4.120
[server3]
hostname=172.30.4.189
As a next step, we’ve started MHA manager:
root@ip-172-30-4-90:~# masterha_manager --conf /etc/s9s_app.cnf
Fri Mar 25 19:51:50 2016 - [info]
172.30.4.120(172.30.4.120:3306) (current master)
+--172.30.4.113(172.30.4.113:3306)
+--172.30.4.189(172.30.4.189:3306)
Fri Mar 25 19:51:50 2016 - [warning] master_ip_failover_script is not defined.
Fri Mar 25 19:51:50 2016 - [warning] shutdown_script is not defined.
Fri Mar 25 19:51:50 2016 - [info] Set master ping interval 3 seconds.
Fri Mar 25 19:51:50 2016 - [warning] secondary_check_script is not defined. It is highly recommended setting it to check master reachability from two or more routes.
Fri Mar 25 19:51:50 2016 - [info] Starting ping health check on 172.30.4.120(172.30.4.120:3306)..
Fri Mar 25 19:51:50 2016 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..
And then we killed the master while running our ‘application’ - sysbench.
root@ip-172-30-4-120:~# killall -9 mysqld mysqld_safe
Failover happened, as expected:
Fri Mar 25 20:18:16 2016 - [info] Master failover to 172.30.4.113(172.30.4.113:3306) completed successfully.
Fri Mar 25 20:18:16 2016 - [info]
----- Failover Report -----
s9s_app: MySQL Master failover 172.30.4.120(172.30.4.120:3306) to 172.30.4.113(172.30.4.113:3306) succeeded
And our application experienced only a couple of seconds of latency spike - no single error was returned and no transaction had to be rolled back. Of course, your mileage may vary - graceful failover was possible only because there were no explicit transactions in our ‘application’. If there were any, those would have failed - you cannot begin a transaction on one host and complete it on another - this obviously won’t work, therefore some rollbacks would have to happen. If you use single statements in auto_commit mode, though, ProxySQL can route them to different hosts.
[ 160s] threads: 6, tps: 0.00, reads: 962.96, writes: 273.70, response time: 123.10ms (95%), errors: 0.00, reconnects: 0.00
[ 161s] threads: 6, tps: 0.00, reads: 86.09, writes: 18.02, response time: 129.72ms (95%), errors: 0.00, reconnects: 0.00
[ 162s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 163s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 164s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 165s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 166s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 167s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 168s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 169s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 170s] threads: 6, tps: 0.00, reads: 0.00, writes: 0.00, response time: 0.00ms (95%), errors: 0.00, reconnects: 0.00
[ 171s] threads: 6, tps: 0.00, reads: 233.28, writes: 75.77, response time: 10724.58ms (95%), errors: 0.00, reconnects: 0.00
[ 172s] threads: 6, tps: 0.00, reads: 849.21, writes: 245.75, response time: 208.91ms (95%), errors: 0.00, reconnects: 0.00
[ 173s] threads: 6, tps: 0.00, reads: 791.15, writes: 228.75, response time: 219.02ms (95%), errors: 0.00, reconnects: 0.00
Query caching
Query caching is always tricky and requires a significant dose of caution. Every query which is cached may return stale data and this may or may not be acceptable to the application. MySQL query cache is available since a long time but it’s far from being a perfect solution. It tends to serialize the workload, it is virtually not usable if you do lots of writes to a table - the relevant cache entries are invalidated very often. In short, it’s not a solution you can use when you are concerned about performance. There are different methods to implement a cache layer in a MySQL environment, but the most popular ones (except MySQL query cache) involve some external solutions (memcached, Redis, Couchbase) and application logic (connect to those databases, retrieve data, insert new data, handle some logic around it). This usually requires the DBA to interact with developers to make a change in this system (unless a DBA is also a developer).
Let’s try to imagine a situation where you, as a DBA, detects a significant increase in the database load. Load is triggered by non-optimal SELECT query. You contacted your developers and confirmed the query can be cached for, let’s say, five seconds. Sounds good to you, but you need to wait until the code is changed, built into a new release, then through the testing process before it is pushed to production. This may take a while, leaving you with overloaded, hot database servers for a day or two. Doesn’t sound good.
ProxySQL can help here. Let’s check our top 10 slow queries using stats_mysql_query_digest table:
MySQL [(none)]> select hostgroup, digest_text, count_star, sum_time, min_time, max_time from stats_mysql_query_digest order by sum_time desc LIMIT 10;
+-----------+-----------------------------------+------------+----------+----------+----------+
| hostgroup | digest_text | count_star | sum_time | min_time | max_time |
+-----------+-----------------------------------+------------+----------+----------+----------+
| 1 | SELECT c FROM sbtest23 WHERE id=? | 26412 | 45799998 | 339 | 1801122 |
| 1 | SELECT c FROM sbtest2 WHERE id=? | 26930 | 45750637 | 333 | 902436 |
| 1 | SELECT c FROM sbtest10 WHERE id=? | 27690 | 45566636 | 336 | 483648 |
| 1 | SELECT c FROM sbtest32 WHERE id=? | 26630 | 45442794 | 336 | 1828579 |
| 1 | SELECT c FROM sbtest26 WHERE id=? | 27040 | 44605656 | 336 | 283511 |
| 1 | SELECT c FROM sbtest7 WHERE id=? | 26590 | 43984049 | 335 | 679433 |
| 1 | SELECT c FROM sbtest4 WHERE id=? | 26380 | 43932585 | 335 | 274789 |
| 1 | SELECT c FROM sbtest1 WHERE id=? | 26520 | 43899458 | 333 | 208173 |
| 1 | SELECT c FROM sbtest17 WHERE id=? | 26270 | 43629776 | 331 | 944539 |
| 1 | SELECT c FROM sbtest30 WHERE id=? | 26410 | 43546491 | 331 | 274292 |
+-----------+-----------------------------------+------------+----------+----------+----------+
10 rows in set (0.00 sec)
As you can see, all of them follow the same pattern, it’s just the table that is different. What we can do now is to create a new rule for this particular type of query and then let ProxySQL cache it for some time.
MySQL [(none)]> INSERT INTO mysql_query_rules (active, match_pattern, destination_hostgroup, cache_ttl, apply) VALUES (1, '^SELECT c FROM sbtest[0-9]{1,2} WHERE id=.*', 1, 1000, 1);
Query OK, 1 row affected (0.00 sec)
MySQL [(none)]> LOAD MYSQL QUERY RULES TO RUNTIME;
Query OK, 0 rows affected (0.00 sec)
What we did here was to add an active rule, we passed a regex pattern matching our queries. We also set cache_ttl to 1000ms and we enabled the ‘apply’ flag which means that no further rule will be checked for queries which match the pattern. Now, let’s check if there are queries which matched this rule:
MySQL [(none)]> SELECT rule_id, match_pattern, hits FROM mysql_query_rules LEFT JOIN stats_mysql_query_rules USING (rule_id);
+---------+---------------------------------------------+--------+
| rule_id | match_pattern | hits |
+---------+---------------------------------------------+--------+
| 3 | ^SELECT .* FOR UPDATE | 0 |
| 4 | ^SELECT .* | 157916 |
| 5 | ^SELECT c FROM sbtest[0-9]{1,2} WHERE id=.* | 112793 |
+---------+---------------------------------------------+--------+
3 rows in set (0.00 sec)
As we can see, our rule is being used. Let’s see what are the results. We need to first reset the contents of the stats_mysql_query_digest table, wait a bit and then check its contents:
MySQL [(none)]> select hostgroup, digest_text, count_star, sum_time, min_time, max_time from stats_mysql_query_digest_reset order by sum_time desc LIMIT 0;
Empty set (0.01 sec)
MySQL [(none)]> select hostgroup, digest_text, count_star, sum_time, min_time, max_time from stats_mysql_query_digest order by sum_time desc LIMIT 10;
+-----------+-----------------------------------------------------------------------+------------+----------+----------+----------+
| hostgroup | digest_text | count_star | sum_time | min_time | max_time |
+-----------+-----------------------------------------------------------------------+------------+----------+----------+----------+
| 0 | UPDATE sbtest19 SET k=k+? WHERE id=? | 34 | 1910928 | 428 | 1851831 |
| 1 | SELECT DISTINCT c FROM sbtest23 WHERE id BETWEEN ? AND ?+? ORDER BY c | 37 | 1849728 | 841 | 1715976 |
| 1 | SELECT DISTINCT c FROM sbtest17 WHERE id BETWEEN ? AND ?+? ORDER BY c | 33 | 1013140 | 868 | 843474 |
| 0 | UPDATE sbtest32 SET c=? WHERE id=? | 30 | 911134 | 435 | 837739 |
| 1 | SELECT c FROM sbtest1 WHERE id BETWEEN ? AND ?+? ORDER BY c | 38 | 768206 | 608 | 635686 |
| 1 | SELECT c FROM sbtest4 WHERE id BETWEEN ? AND ?+? | 40 | 405373 | 577 | 287515 |
| 1 | SELECT DISTINCT c FROM sbtest3 WHERE id BETWEEN ? AND ?+? ORDER BY c | 41 | 373227 | 842 | 225387 |
| 1 | SELECT SUM(K) FROM sbtest32 WHERE id BETWEEN ? AND ?+? | 29 | 348709 | 439 | 303660 |
| 1 | SELECT c FROM sbtest7 WHERE id BETWEEN ? AND ?+? ORDER BY c | 33 | 336446 | 603 | 169885 |
| 1 | SELECT c FROM sbtest27 WHERE id BETWEEN ? AND ?+? | 49 | 296659 | 537 | 103047 |
+-----------+-----------------------------------------------------------------------+------------+----------+----------+----------+
10 rows in set (0.00 sec)
As expected, our problematic query is gone.
We can’t stress it enough - you have to be sure you can cache a query before you enable the cache in ProxySQL. Additionally, at this moment it’s more of a stub than full functionality - it lacks some features like limiting memory utilization. It definitely won’t replace your cache layer but may save your database in some cases.
Query rewriting
Let’s imagine this situation - a DBA identified a query which is not optimal and causes significant impact on the database. The query can be easily rewritten but this process requires a code change in the application, and as a result, developers have to be involved, new build has to be prepared, tested and then deployed - all of that has to happen while your databases are on fire. ProxySQL gives you an option to rewrite queries - let’s take a look.
Assume this is our slow query.
SELECT DISTINCT c FROM sbtest16 WHERE id BETWEEN ? AND ?+? ORDER BY c
As you can see, we have a query hitting different tables (sbtest16 is an example here but it uses all 32 tables created by sysbench) and has different BETWEEN arguments. Let’s assume that a correct, more optimal version of this query would be:
SELECT DISTINCT c FROM sbtest16 WHERE id = ?+? ORDER BY c
Of course, this is a completely different query but for the purpose of this post, we’ll pretend it’s our desired query. What can we do? We need to create a rule in mysql_query_rules table with a correct regex to catch the query and a new query version stored in ‘replace_pattern’ column. It’s very important to keep in mind that the match has to be extremely precise - it has to match only the query you intend to match. Be strict with your regex, otherwise you may end up with broken queries.
MySQL [(none)]> INSERT INTO mysql_query_rules (active, match_pattern, replace_pattern, destination_hostgroup, apply) VALUES (1, '^SELECT DISTINCT c FROM sbtest([0-9]{1,2}) WHERE id BETWEEN ([0-9]+) AND ([0-9]+)\+([0-9]+) ORDER BY c$', 'SELECT DISTINCT c FROM sbtest\1 WHERE id = \3 + \4 ORDER BY c', 1, 1);
Query OK, 1 row affected (0.00 sec)
MySQL [(none)]> LOAD MYSQL QUERY RULES TO RUNTIME;
Query OK, 0 rows affected (0.00 sec)
MySQL [(none)]> SELECT rule_id, match_pattern, hits FROM mysql_query_rules LEFT JOIN stats_mysql_query_rules USING (rule_id);
+---------+---------------------------------------------------------------------------------------------------------+-------+
| rule_id | match_pattern | hits |
+---------+---------------------------------------------------------------------------------------------------------+-------+
| 3 | ^SELECT .* FOR UPDATE | 0 |
| 4 | ^SELECT .* | 21940 |
| 5 | ^SELECT c FROM sbtest[0-9]{1,2} WHERE id=.* | 15670 |
| 7 | ^SELECT DISTINCT c FROM sbtest([0-9]{1,2}) WHERE id BETWEEN ([0-9]+) AND ([0-9]+)+([0-9]+) ORDER BY c$ | 1568 |
+---------+---------------------------------------------------------------------------------------------------------+-------+
4 rows in set (0.00 sec)
As we can see, the hits counter started to increase which means the query is matching correctly. It doesn’t mean that the rewrite works correctly though. For that, you may want to check ProxySQL’s error log (by default located in /var/lib/proxysql/proxysql.log). You may see entries like this one:
re2/re2.cc:881: invalid rewrite pattern: SELECT DISTINCT c FROM sbtest\1 WHERE id = \3 \+ \4 ORDER BY c
which basically means that the rewrite pattern is not correct and rewrite cannot be executed. In this particular case, an issue was caused by unnecessary escape in ‘\3 \+ \4’ - ‘+’character shouldn’t be escaped here.
Final verification can be done in the ProxySQL’s stats_mysql_query_digest table:
MySQL [(none)]> SELECT hostgroup hg, sum_time, count_star, digest_text FROM stats_mysql_query_digest WHERE digest_text LIKE 'SELECT DISTINCT%' ORDER BY sum_time DESC LIMIT 2;
+----+----------+------------+-----------------------------------------------------------------------+
| hg | sum_time | count_star | digest_text |
+----+----------+------------+-----------------------------------------------------------------------+
| 1 | 1121190 | 275 | SELECT DISTINCT c FROM sbtest21 WHERE id BETWEEN ? AND ?+? ORDER BY c |
| 1 | 1072667 | 238 | SELECT DISTINCT c FROM sbtest26 WHERE id BETWEEN ? AND ?+? ORDER BY c |
+----+----------+------------+-----------------------------------------------------------------------+
2 rows in set (0.01 sec)
Our SELECT DISTINCT queries have been rewritten. Right now, ProxySQL does not have an option to test your rewrites without modifying live traffic therefore you have to be very cautious when you use it. A way to test rewrites will be added in an upcoming version.
Query statistics
Let’s imagine that, as the DBA, you are trying to understand the workload of the databases. The reasons for this are numerous - you can be a new DBA who’s not familiar with the query mix, you can be investigating different issues around database performance, you can be an external consultant who’s getting up to speed with your customer’s database layer.
All those situations have one thing in common - you want to see what kind of queries your databases are executing. Of course, there are numerous ways to do that - you can collect network data using tcpdump, you can enable slow query log. If you’re sending all of your traffic through the proxy layer, maybe you could use what’s already in place to give you some statistics?
In ProxySQL, there are a couple of tables in ‘stats’ schema which store interesting data. For starters, ‘stats_mysql_commands_counters’ table, which stores information about different types of queries, can be used to get some idea of how fast they are.
MySQL [(none)]> SELECT * FROM stats_mysql_commands_counters WHERE Total_cnt >0;
+---------+---------------+-----------+-----------+-----------+----------+---------+----------+----------+-----------+-----------+--------+--------+---------+----------+
| Command | Total_Time_us | Total_cnt | cnt_100us | cnt_500us | cnt_1ms | cnt_5ms | cnt_10ms | cnt_50ms | cnt_100ms | cnt_500ms | cnt_1s | cnt_5s | cnt_10s | cnt_INFs |
+---------+---------------+-----------+-----------+-----------+----------+---------+----------+----------+-----------+-----------+--------+--------+---------+----------+
| DELETE | 11316248971 | 4551565 | 0 | 2907245 | 778419 | 336596 | 207405 | 305059 | 13595 | 2822 | 172 | 252 | 0 | 0 |
| INSERT | 4590870732 | 4551565 | 2 | 3166500 | 917052 | 354698 | 49826 | 59129 | 3169 | 1103 | 34 | 52 | 0 | 0 |
| SELECT | 46929819703 | 63722353 | 45467962 | 4358571 | 10661088 | 1401741 | 505177 | 1241246 | 68037 | 17490 | 460 | 580 | 1 | 0 |
| UPDATE | 25651099588 | 9103156 | 1 | 5328953 | 1800909 | 806071 | 451168 | 675399 | 32361 | 7312 | 416 | 541 | 9 | 16 |
+---------+---------------+-----------+-----------+-----------+----------+---------+----------+----------+-----------+-----------+--------+--------+---------+----------+
4 rows in set (0.00 sec)
Here, we have a nice overview of how fast the different type of queries are. Looking at selects, we can tell that majority of them finish within 1ms, which is pretty ok.
Another interesting table is ‘stats_mysql_query_digest’ which contains information about exact queries. There’s also ‘stats_mysql_query_digest_reset’ table, which, when queried, clears data in the ‘stats_mysql_query_digest’ table - useful to check current data, without any historical information.
MySQL [(none)]> SELECT * FROM stats_mysql_query_digest LIMIT 1;
+-----------+------------+----------+--------------------+-----------------------------------+------------+------------+------------+----------+----------+----------+
| hostgroup | schemaname | username | digest | digest_text | count_star | first_seen | last_seen | sum_time | min_time | max_time |
+-----------+------------+----------+--------------------+-----------------------------------+------------+------------+------------+----------+----------+----------+
| 1 | sbtest | sbtest | 0x2395C0F0FBDF6C6D | SELECT c FROM sbtest30 WHERE id=? | 1289 | 1457954527 | 1457990048 | 2395914 | 304 | 128928 |
+-----------+------------+----------+--------------------+-----------------------------------+------------+------------+------------+----------+----------+----------+
1 row in set (0.01 sec)
Both of those tables give you access to details like the hostgroup where the query was routed, default schema and user which executed the query. There’s also a digest, standardised query format, number of occurrences and couple of statistical data on the query - when it was first and last seen, summary of the execution time, maximum and minimum execution time. Sure, this is by no means data comparable with information you can collect using slowlog or tcpdump and, for example, pt-query-digest. It’s still lot of data which can be useful in building a broader picture of the database workload.
We’ve reached the end of this post, hopefully it gives some insight into how ProxySQL operates and how you can benefit from it. In a future post, we’ll write about how to use ProxySQL with Galera Cluster.