What is SysBench? If you work with MySQL on a regular basis, then you most probably have heard of it. SysBench has been in the MySQL ecosystem for a long time. It was originally written by Peter Zaitsev, back in 2004. Its purpose was to provide a tool to run synthetic benchmarks of MySQL and the hardware it runs on. It was designed to run CPU, memory and I/O tests. It had also an option to execute OLTP workload on a MySQL database. OLTP stands for online transaction processing, typical workload for online applications like e-commerce, order entry or financial transaction systems.
In this blog post, we will focus on the SQL benchmark feature but keep in mind that hardware benchmarks can also be very useful in identifying issues on database servers. For example, I/O benchmark was intended to simulate InnoDB I/O workload while CPU tests involve simulation of highly concurrent, multi-treaded environment along with tests for mutex contentions - something which also resembles a database type of workload.
SysBench history and architecture
As mentioned, SysBench was originally created in 2004 by Peter Zaitsev. Soon after, Alexey Kopytov took over its development. It reached version 0.4.12 and the development halted. After a long break Alexey started to work on SysBench again in 2016. Soon version 0.5 has been released with OLTP benchmark rewritten to use LUA-based scripts. Then, in 2017, SysBench 1.0 was released. This was like day and night compared to the old, 0.4.12 version. First and the foremost, instead of hardcoded scripts, now we have the ability to customize benchmarks using LUA. For instance, Percona created TPCC-like benchmark which can be executed using SysBench. Let’s take a quick look at the current SysBench architecture.
SysBench is a C binary which uses LUA scripts to execute benchmarks. Those scripts have to:
- Handle input from command line parameters
- Define all of the modes which the benchmark is supposed to use (prepare, run, cleanup)
- Prepare all of the data
- Define how the benchmark will be executed (what queries will look like etc)
Scripts can utilize multiple connections to the database, they can also process results should you want to create complex benchmarks where queries depend on the result set of previous queries. With SysBench 1.0 it is possible to create latency histograms. It is also possible for the LUA scripts to catch and handle errors through error hooks. There’s support for parallelization in the LUA scripts, multiple queries can be executed in parallel, making, for example, provisioning much faster. Last but not least, multiple output formats are now supported. Before SysBench generated only human-readable output. Now it is possible to generate it as CSV or JSON, making it much easier to do post-processing and generate graphs using, for example, gnuplot or feed the data into Prometheus, Graphite or similar datastore.
Why SysBench?
The main reason why SysBench became popular is the fact that it is simple to use. Someone without prior knowledge can start to use it within minutes. It also provides, by default, benchmarks which cover most of the cases - OLTP workloads, read-only or read-write, primary key lookups and primary key updates. All which caused most of the issues for MySQL, up to MySQL 8.0. This was also a reason why SysBench was so popular in different benchmarks and comparisons published on the Internet. Those posts helped to promote this tool and made it into the go-to synthetic benchmark for MySQL.
Another good thing about SysBench is that, since version 0.5 and incorporation of LUA, anyone can prepare any kind of benchmark. We already mentioned TPCC-like benchmark but anyone can craft something which will resemble her production workload. We are not saying it is simple, it will be most likely a time-consuming process, but having this ability is beneficial if you need to prepare a custom benchmark.
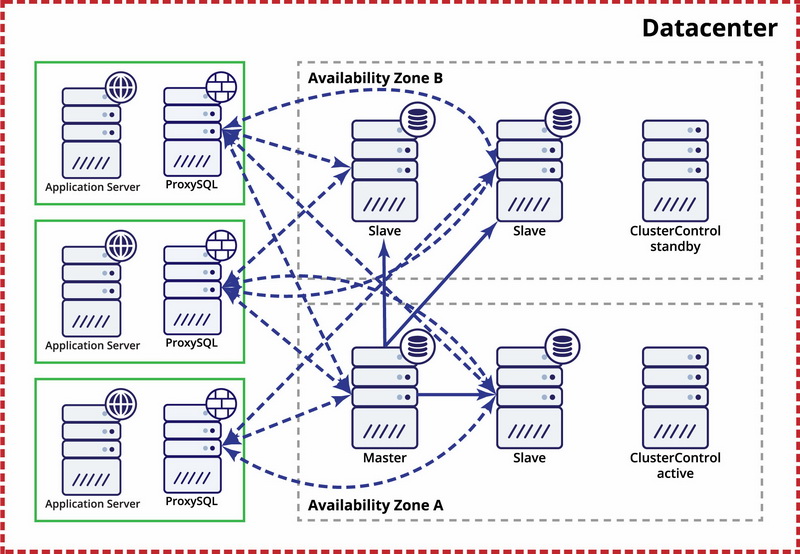
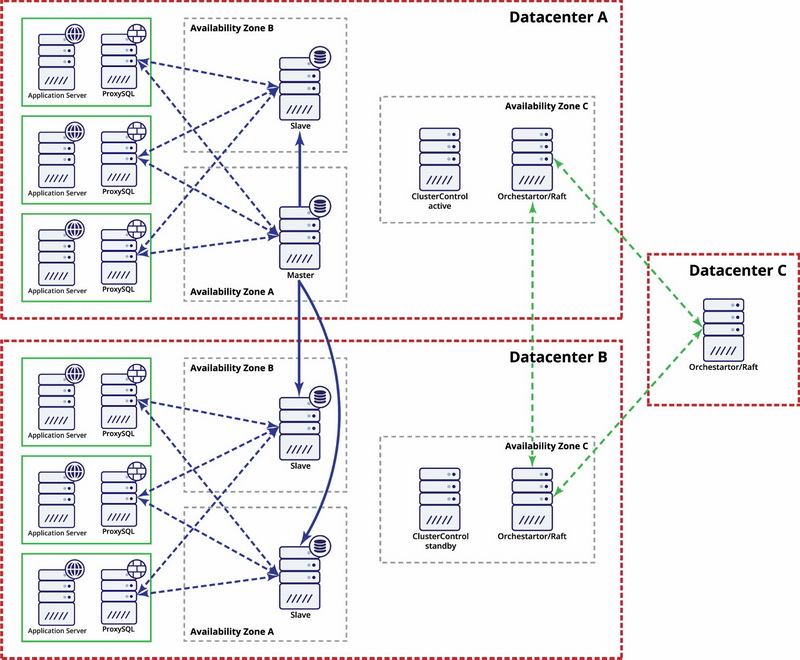
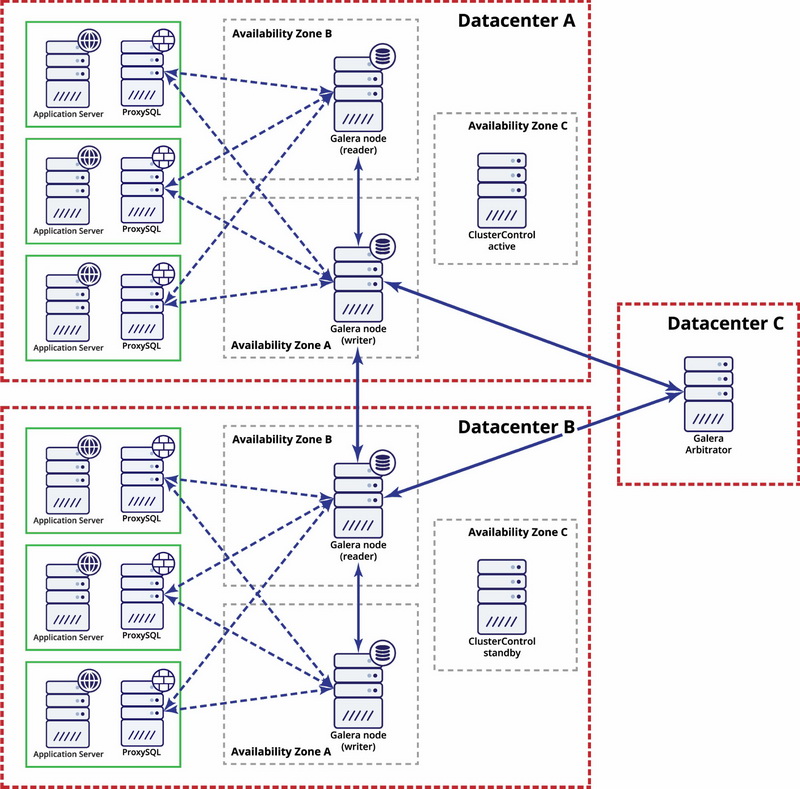
Being a synthetic benchmark, SysBench is not a tool which you can use to tune configurations of your MySQL servers (unless you prepared LUA scripts with custom workload or your workload happen to be very similar to the benchmark workloads that SysBench comes with). What it is great for is to compare performance of different hardware. You can easily compare performance of, let’s say, different type of nodes offered by your cloud provider and maximum QPS (queries per second) they offer. Knowing that metric and knowing what you pay for given node, you can then calculate even more important metric - QP$ (queries per dollar). This will allow you to identify what node type to use when building a cost-efficient environment. Of course, SysBench can be used also for initial tuning and assessing feasibility of a given design. Let’s say we build a Galera cluster spanning across the globe - North America, EU, Asia. How many inserts per second can such a setup handle? What would be the commit latency? Does it even make sense to do a proof of concept or maybe network latency is high enough that even a simple workload does not work as you would expect it to.
What about stress-testing? Not everyone has moved to the cloud, there are still companies preferring to build their own infrastructure. Every new server acquired should go through a warm-up period during which you will stress it to pinpoint potential hardware defects. In this case SysBench can also help. Either by executing OLTP workload which overloads the server, or you can also use dedicated benchmarks for CPU, disk and memory.
As you can see, there are many cases in which even a simple, synthetic benchmark can be very useful. In the next paragraph we will look at what we can do with SysBench.
What SysBench can do for you?
What tests you can run?
As mentioned at the beginning, we will focus on OLTP benchmarks and just as a reminder we’ll repeat that SysBench can also be used to perform I/O, CPU and memory tests. Let’s take a look at the benchmarks that SysBench 1.0 comes with (we removed some helper LUA files and non-database LUA scripts from this list).
-rwxr-xr-x 1 root root 1.5K May 30 07:46 bulk_insert.lua
-rwxr-xr-x 1 root root 1.3K May 30 07:46 oltp_delete.lua
-rwxr-xr-x 1 root root 2.4K May 30 07:46 oltp_insert.lua
-rwxr-xr-x 1 root root 1.3K May 30 07:46 oltp_point_select.lua
-rwxr-xr-x 1 root root 1.7K May 30 07:46 oltp_read_only.lua
-rwxr-xr-x 1 root root 1.8K May 30 07:46 oltp_read_write.lua
-rwxr-xr-x 1 root root 1.1K May 30 07:46 oltp_update_index.lua
-rwxr-xr-x 1 root root 1.2K May 30 07:46 oltp_update_non_index.lua
-rwxr-xr-x 1 root root 1.5K May 30 07:46 oltp_write_only.lua
-rwxr-xr-x 1 root root 1.9K May 30 07:46 select_random_points.lua
-rwxr-xr-x 1 root root 2.1K May 30 07:46 select_random_ranges.lua
Let’s go through them one by one.
First, bulk_insert.lua. This test can be used to benchmark the ability of MySQL to perform multi-row inserts. This can be quite useful when checking, for example, performance of replication or Galera cluster. In the first case, it can help you answer a question: “how fast can I insert before replication lag will kick in?”. In the later case, it will tell you how fast data can be inserted into a Galera cluster given the current network latency.
All oltp_* scripts share a common table structure. First two of them (oltp_delete.lua and oltp_insert.lua) execute single DELETE and INSERT statements. Again, this could be a test for either replication or Galera cluster - push it to the limits and see what amount of inserting or purging it can handle. We also have other benchmarks focused on particular functionality - oltp_point_select, oltp_update_index and oltp_update_non_index. These will execute a subset of queries - primary key-based selects, index-based updates and non-index-based updates. If you want to test some of these functionalities, the tests are there. We also have more complex benchmarks which are based on OLTP workloads: oltp_read_only, oltp_read_write and oltp_write_only. You can run either a read-only workload, which will consist of different types of SELECT queries, you can run only writes (a mix of DELETE, INSERT and UPDATE) or you can run a mix of those two. Finally, using select_random_points and select_random_ranges you can run some random SELECT either using random points in IN() list or random ranges using BETWEEN.
How you can configure a benchmark?
What is also important, benchmarks are configurable - you can run different workload patterns using the same benchmark. Let’s take a look at the two most common benchmarks to execute. We’ll have a deep dive into OLTP read_only and OLTP read_write benchmarks. First of all, SysBench has some general configuration options. We will discuss here only the most important ones, you can check all of them by running:
sysbench --help
Let’s take a look at them.
--threads=N number of threads to use [1]
You can define what kind of concurrency you’d like SysBench to generate. MySQL, as every software, has some scalability limitations and its performance will peak at some level of concurrency. This setting helps to simulate different concurrencies for a given workload and check if it already has passed the sweet spot.
--events=N limit for total number of events [0]
--time=N limit for total execution time in seconds [10]
Those two settings govern how long SysBench should keep running. It can either execute some number of queries or it can keep running for a predefined time.
--warmup-time=N execute events for this many seconds with statistics disabled before the actual benchmark run with statistics enabled [0]
This is self-explanatory. SysBench generates statistical results from the tests and those results may be affected if MySQL is in a cold state. Warmup helps to identify “regular” throughput by executing benchmark for a predefined time, allowing to warm up the cache, buffer pools etc.
--rate=N average transactions rate. 0 for unlimited rate [0]
By default SysBench will attempt to execute queries as fast as possible. To simulate slower traffic this option may be used. You can define here how many transactions should be executed per second.
--report-interval=N periodically report intermediate statistics with a specified interval in seconds. 0 disables intermediate reports [0]
By default SysBench generates a report after it completed its run and no progress is reported while the benchmark is running. Using this option you can make SysBench more verbose while the benchmark still runs.
--rand-type=STRING random numbers distribution {uniform, gaussian, special, pareto, zipfian} to use by default [special]
SysBench gives you ability to generate different types of data distribution. All of them may have their own purposes. Default option, ‘special’, defines several (it is configurable) hot-spots in the data, something which is quite common in web applications. You can also use other distributions if your data behaves in a different way. By making a different choice here you can also change the way your database is stressed. For example, uniform distribution, where all of the rows have the same likeliness of being accessed, is much more memory-intensive operation. It will use more buffer pool to store all of the data and it will be much more disk-intensive if your data set won’t fit in memory. On the other hand, special distribution with couple of hot-spots will put less stress on the disk as hot rows are more likely to be kept in the buffer pool and access to rows stored on disk is much less likely. For some of the data distribution types, SysBench gives you more tweaks. You can find this info in ‘sysbench --help’ output.
--db-ps-mode=STRING prepared statements usage mode {auto, disable} [auto]
Using this setting you can decide if SysBench should use prepared statements (as long as they are available in the given datastore - for MySQL it means PS will be enabled by default) or not. This may make a difference while working with proxies like ProxySQL or MaxScale - they should treat prepared statements in a special way and all of them should be routed to one host making it impossible to test scalability of the proxy.
In addition to the general configuration options, each of the tests may have its own configuration. You can check what is possible by running:
root@vagrant:~# sysbench ./sysbench/src/lua/oltp_read_write.lua help
sysbench 1.1.0-2e6b7d5 (using bundled LuaJIT 2.1.0-beta3)
oltp_read_only.lua options:
--distinct_ranges=N Number of SELECT DISTINCT queries per transaction [1]
--sum_ranges=N Number of SELECT SUM() queries per transaction [1]
--skip_trx[=on|off] Don't start explicit transactions and execute all queries in the AUTOCOMMIT mode [off]
--secondary[=on|off] Use a secondary index in place of the PRIMARY KEY [off]
--create_secondary[=on|off] Create a secondary index in addition to the PRIMARY KEY [on]
--index_updates=N Number of UPDATE index queries per transaction [1]
--range_size=N Range size for range SELECT queries [100]
--auto_inc[=on|off] Use AUTO_INCREMENT column as Primary Key (for MySQL), or its alternatives in other DBMS. When disabled, use client-generated IDs [on]
--delete_inserts=N Number of DELETE/INSERT combinations per transaction [1]
--tables=N Number of tables [1]
--mysql_storage_engine=STRING Storage engine, if MySQL is used [innodb]
--non_index_updates=N Number of UPDATE non-index queries per transaction [1]
--table_size=N Number of rows per table [10000]
--pgsql_variant=STRING Use this PostgreSQL variant when running with the PostgreSQL driver. The only currently supported variant is 'redshift'. When enabled, create_secondary is automatically disabled, and delete_inserts is set to 0
--simple_ranges=N Number of simple range SELECT queries per transaction [1]
--order_ranges=N Number of SELECT ORDER BY queries per transaction [1]
--range_selects[=on|off] Enable/disable all range SELECT queries [on]
--point_selects=N Number of point SELECT queries per transaction [10]
Again, we will discuss the most important options from here. First of all, you have a control of how exactly a transaction will look like. Generally speaking, it consists of different types of queries - INSERT, DELETE, different type of SELECT (point lookup, range, aggregation) and UPDATE (indexed, non-indexed). Using variables like:
--distinct_ranges=N Number of SELECT DISTINCT queries per transaction [1]
--sum_ranges=N Number of SELECT SUM() queries per transaction [1]
--index_updates=N Number of UPDATE index queries per transaction [1]
--delete_inserts=N Number of DELETE/INSERT combinations per transaction [1]
--non_index_updates=N Number of UPDATE non-index queries per transaction [1]
--simple_ranges=N Number of simple range SELECT queries per transaction [1]
--order_ranges=N Number of SELECT ORDER BY queries per transaction [1]
--point_selects=N Number of point SELECT queries per transaction [10]
--range_selects[=on|off] Enable/disable all range SELECT queries [on]
You can define what a transaction should look like. As you can see by looking at the default values, majority of queries are SELECTs - mainly point selects but also different types of range SELECTs (you can disable all of them by setting range_selects to off). You can tweak the workload towards more write-heavy workload by increasing the number of updates or INSERT/DELETE queries. It is also possible to tweak settings related to secondary indexes, auto increment but also data set size (number of tables and how many rows each of them should hold). This lets you customize your workload quite nicely.
--skip_trx[=on|off] Don't start explicit transactions and execute all queries in the AUTOCOMMIT mode [off]
This is another setting, quite important when working with proxies. By default, SysBench will attempt to execute queries in explicit transaction. This way the dataset will stay consistent and not affected: SysBench will, for example, execute INSERT and DELETE on the same row, making sure the data set will not grow (impacting your ability to reproduce results). However, proxies will treat explicit transactions differently - all queries executed within a transaction should be executed on the same host, thus removing the ability to scale the workload. Please keep in mind that disabling transactions will result in data set diverging from the initial point. It may also trigger some issues like duplicate key errors or such. To be able to disable transactions you may also want to look into:
--mysql-ignore-errors=[LIST,...] list of errors to ignore, or "all" [1213,1020,1205]
This setting allows you to specify error codes from MySQL which SysBench should ignore (and not kill the connection). For example, to ignore errors like: error 1062 (Duplicate entry '6' for key 'PRIMARY') you should pass this error code: --mysql-ignore-errors=1062
What is also important, each benchmark should present a way to provision a data set for tests, run them and then clean it up after the tests complete. This is done using ‘prepare’, ‘run’ and ‘cleanup’ commands. We will show how this is done in the next section.
Examples
In this section we’ll go through some examples of what SysBench can be used for. As mentioned earlier, we’ll focus on the two most popular benchmarks - OLTP read only and OLTP read/write. Sometimes it may make sense to use other benchmarks, but at least we’ll be able to show you how those two can be customized.
Primary Key lookups
First of all, we have to decide which benchmark we will run, read-only or read-write. Technically speaking it does not make a difference as we can remove writes from R/W benchmark. Let’s focus on the read-only one.
As a first step, we have to prepare a data set. We need to decide how big it should be. For this particular benchmark, using default settings (so, secondary indexes are created), 1 million rows will result in ~240 MB of data. Ten tables, 1000 000 rows each equals to 2.4GB:
root@vagrant:~# du -sh /var/lib/mysql/sbtest/
2.4G /var/lib/mysql/sbtest/
root@vagrant:~# ls -alh /var/lib/mysql/sbtest/
total 2.4G
drwxr-x--- 2 mysql mysql 4.0K Jun 1 12:12 .
drwxr-xr-x 6 mysql mysql 4.0K Jun 1 12:10 ..
-rw-r----- 1 mysql mysql 65 Jun 1 12:08 db.opt
-rw-r----- 1 mysql mysql 8.5K Jun 1 12:12 sbtest10.frm
-rw-r----- 1 mysql mysql 240M Jun 1 12:12 sbtest10.ibd
-rw-r----- 1 mysql mysql 8.5K Jun 1 12:10 sbtest1.frm
-rw-r----- 1 mysql mysql 240M Jun 1 12:10 sbtest1.ibd
-rw-r----- 1 mysql mysql 8.5K Jun 1 12:10 sbtest2.frm
-rw-r----- 1 mysql mysql 240M Jun 1 12:10 sbtest2.ibd
-rw-r----- 1 mysql mysql 8.5K Jun 1 12:10 sbtest3.frm
-rw-r----- 1 mysql mysql 240M Jun 1 12:10 sbtest3.ibd
-rw-r----- 1 mysql mysql 8.5K Jun 1 12:10 sbtest4.frm
-rw-r----- 1 mysql mysql 240M Jun 1 12:10 sbtest4.ibd
-rw-r----- 1 mysql mysql 8.5K Jun 1 12:11 sbtest5.frm
-rw-r----- 1 mysql mysql 240M Jun 1 12:11 sbtest5.ibd
-rw-r----- 1 mysql mysql 8.5K Jun 1 12:11 sbtest6.frm
-rw-r----- 1 mysql mysql 240M Jun 1 12:11 sbtest6.ibd
-rw-r----- 1 mysql mysql 8.5K Jun 1 12:11 sbtest7.frm
-rw-r----- 1 mysql mysql 240M Jun 1 12:11 sbtest7.ibd
-rw-r----- 1 mysql mysql 8.5K Jun 1 12:11 sbtest8.frm
-rw-r----- 1 mysql mysql 240M Jun 1 12:11 sbtest8.ibd
-rw-r----- 1 mysql mysql 8.5K Jun 1 12:12 sbtest9.frm
-rw-r----- 1 mysql mysql 240M Jun 1 12:12 sbtest9.ibd
This should give you idea how many tables you want and how big they should be. Let’s say we want to test in-memory workload so we want to create tables which will fit into InnoDB buffer pool. On the other hand, we want also to make sure there are enough tables not to become a bottleneck (or, that the amount of tables matches what you would expect in your production setup). Let’s prepare our dataset. Please keep in mind that, by default, SysBench looks for ‘sbtest’ schema which has to exist before you prepare the data set. You may have to create it manually.
root@vagrant:~# sysbench /root/sysbench/src/lua/oltp_read_only.lua --threads=4 --mysql-host=10.0.0.126 --mysql-user=sbtest --mysql-password=pass --mysql-port=3306 --tables=10 --table-size=1000000 prepare
sysbench 1.1.0-2e6b7d5 (using bundled LuaJIT 2.1.0-beta3)
Initializing worker threads...
Creating table 'sbtest2'...
Creating table 'sbtest3'...
Creating table 'sbtest4'...
Creating table 'sbtest1'...
Inserting 1000000 records into 'sbtest2'
Inserting 1000000 records into 'sbtest4'
Inserting 1000000 records into 'sbtest3'
Inserting 1000000 records into 'sbtest1'
Creating a secondary index on 'sbtest2'...
Creating a secondary index on 'sbtest3'...
Creating a secondary index on 'sbtest1'...
Creating a secondary index on 'sbtest4'...
Creating table 'sbtest6'...
Inserting 1000000 records into 'sbtest6'
Creating table 'sbtest7'...
Inserting 1000000 records into 'sbtest7'
Creating table 'sbtest5'...
Inserting 1000000 records into 'sbtest5'
Creating table 'sbtest8'...
Inserting 1000000 records into 'sbtest8'
Creating a secondary index on 'sbtest6'...
Creating a secondary index on 'sbtest7'...
Creating a secondary index on 'sbtest5'...
Creating a secondary index on 'sbtest8'...
Creating table 'sbtest10'...
Inserting 1000000 records into 'sbtest10'
Creating table 'sbtest9'...
Inserting 1000000 records into 'sbtest9'
Creating a secondary index on 'sbtest10'...
Creating a secondary index on 'sbtest9'...
Once we have our data, let’s prepare a command to run the test. We want to test Primary Key lookups therefore we will disable all other types of SELECT. We will also disable prepared statements as we want to test regular queries. We will test low concurrency, let’s say 16 threads. Our command may look like below:
sysbench /root/sysbench/src/lua/oltp_read_only.lua --threads=16 --events=0 --time=300 --mysql-host=10.0.0.126 --mysql-user=sbtest --mysql-password=pass --mysql-port=3306 --tables=10 --table-size=1000000 --range_selects=off --db-ps-mode=disable --report-interval=1 run
What did we do here? We set the number of threads to 16. We decided that we want our benchmark to run for 300 seconds, without a limit of executed queries. We defined connectivity to the database, number of tables and their size. We also disabled all range SELECTs, we also disabled prepared statements. Finally, we set report interval to one second. This is how a sample output may look like:
[ 297s ] thds: 16 tps: 97.21 qps: 1127.43 (r/w/o: 935.01/0.00/192.41) lat (ms,95%): 253.35 err/s: 0.00 reconn/s: 0.00
[ 298s ] thds: 16 tps: 195.32 qps: 2378.77 (r/w/o: 1985.13/0.00/393.64) lat (ms,95%): 189.93 err/s: 0.00 reconn/s: 0.00
[ 299s ] thds: 16 tps: 178.02 qps: 2115.22 (r/w/o: 1762.18/0.00/353.04) lat (ms,95%): 155.80 err/s: 0.00 reconn/s: 0.00
[ 300s ] thds: 16 tps: 217.82 qps: 2640.92 (r/w/o: 2202.27/0.00/438.65) lat (ms,95%): 125.52 err/s: 0.00 reconn/s: 0.00
Every second we see a snapshot of workload stats. This is quite useful to track and plot - final report will give you averages only. Intermediate results will make it possible to track the performance on a second by second basis. The final report may look like below:
SQL statistics:
queries performed:
read: 614660
write: 0
other: 122932
total: 737592
transactions: 61466 (204.84 per sec.)
queries: 737592 (2458.08 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
Throughput:
events/s (eps): 204.8403
time elapsed: 300.0679s
total number of events: 61466
Latency (ms):
min: 24.91
avg: 78.10
max: 331.91
95th percentile: 137.35
sum: 4800234.60
Threads fairness:
events (avg/stddev): 3841.6250/20.87
execution time (avg/stddev): 300.0147/0.02
You will find here information about executed queries and other (BEGIN/COMMIT) statements. You’ll learn how many transactions were executed, how many errors happened, what was the throughput and total elapsed time. You can also check latency metrics and the query distribution across threads.
If we were interested in latency distribution, we could also pass ‘--histogram’ argument to SysBench. This results in an additional output like below:
Latency histogram (values are in milliseconds)
value ------------- distribution ------------- count
29.194 |****** 1
30.815 |****** 1
31.945 |*********** 2
33.718 |****** 1
34.954 |*********** 2
35.589 |****** 1
37.565 |*********************** 4
38.247 |****** 1
38.942 |****** 1
39.650 |*********** 2
40.370 |*********** 2
41.104 |***************** 3
41.851 |***************************** 5
42.611 |***************** 3
43.385 |***************** 3
44.173 |*********** 2
44.976 |**************************************** 7
45.793 |*********************** 4
46.625 |*********** 2
47.472 |***************************** 5
48.335 |**************************************** 7
49.213 |*********** 2
50.107 |********************************** 6
51.018 |*********************** 4
51.945 |**************************************** 7
52.889 |***************** 3
53.850 |***************** 3
54.828 |*********************** 4
55.824 |*********** 2
57.871 |*********** 2
58.923 |*********** 2
59.993 |****** 1
61.083 |****** 1
63.323 |*********** 2
66.838 |****** 1
71.830 |****** 1
Once we are good with our results, we can clean up the data:
sysbench /root/sysbench/src/lua/oltp_read_only.lua --threads=16 --events=0 --time=300 --mysql-host=10.0.0.126 --mysql-user=sbtest --mysql-password=pass --mysql-port=3306 --tables=10 --table-size=1000000 --range_selects=off --db-ps-mode=disable --report-interval=1 cleanup
Write-heavy traffic
Let’s imagine here that we want to execute a write-heavy (but not write-only) workload and, for example, test I/O subsystem’s performance. First of all, we have to decide how big the dataset should be. We’ll assume ~48GB of data (20 tables, 10 000 000 rows each). We need to prepare it. This time we will use the read-write benchmark.
root@vagrant:~# sysbench /root/sysbench/src/lua/oltp_read_write.lua --threads=4 --mysql-host=10.0.0.126 --mysql-user=sbtest --mysql-password=pass --mysql-port=3306 --tables=20 --table-size=10000000 prepare
Once this is done, we can tweak the defaults to force more writes into the query mix:
root@vagrant:~# sysbench /root/sysbench/src/lua/oltp_read_write.lua --threads=16 --events=0 --time=300 --mysql-host=10.0.0.126 --mysql-user=sbtest --mysql-password=pass --mysql-port=3306 --tables=20 --delete_inserts=10 --index_updates=10 --non_index_updates=10 --table-size=10000000 --db-ps-mode=disable --report-interval=1 run
As you can see from the intermediate results, transactions are now on a write-heavy side:
[ 5s ] thds: 16 tps: 16.99 qps: 946.31 (r/w/o: 231.83/680.50/33.98) lat (ms,95%): 1258.08 err/s: 0.00 reconn/s: 0.00
[ 6s ] thds: 16 tps: 17.01 qps: 955.81 (r/w/o: 223.19/698.59/34.03) lat (ms,95%): 1032.01 err/s: 0.00 reconn/s: 0.00
[ 7s ] thds: 16 tps: 12.00 qps: 698.91 (r/w/o: 191.97/482.93/24.00) lat (ms,95%): 1235.62 err/s: 0.00 reconn/s: 0.00
[ 8s ] thds: 16 tps: 14.01 qps: 683.43 (r/w/o: 195.12/460.29/28.02) lat (ms,95%): 1533.66 err/s: 0.00 reconn/s: 0.00
Understanding the results
As we showed above, SysBench is a great tool which can help to pinpoint some of the performance issues of MySQL or MariaDB. It can also be used for initial tuning of your database configuration. Of course, you have to keep in mind that, to get the best out of your benchmarks, you have to understand why results look like they do. This would require insights into the MySQL internal metrics using monitoring tools, for instance, ClusterControl. This is quite important to remember - if you don’t understand why the performance was like it was, you may draw incorrect conclusions out of the benchmarks. There is always a bottleneck, and SysBench can help raise the performance issues, which you then have to identify.